Why Agent Orcha is built
the way it is.
Every architectural decision in Agent Orcha exists to solve a specific problem that technology leaders face when deploying AI in regulated, high-stakes environments. This page explains the reasoning behind each one.
Why open source is non-negotiable
No vendor lock-in — ever
MIT-licensed. If we disappear tomorrow, your infrastructure keeps running. Fork, modify, and extend without permission.
Inspectable by your security team
Every network call, data path, and permission boundary is auditable before deployment. Trust through verification, not vendor claims.
No licensing leverage
No per-seat fees, no usage caps, no enterprise tier upgrades. The platform is the platform.
Regulatory alignment
Government and defense increasingly require source code access for AI systems. Open source satisfies this by default.
Why model-agnostic — not "supports multiple models"
Infrastructure outlives any model
Models are configured in a JSON file and referenced by name. Swap from GPT-4 to Claude to a local Qwen model by changing one line.
Negotiate from strength
When switching providers requires no engineering cost, vendor relationships become choice, not dependency.
Right model for the job
Assign different models to different agents based on the task, cost, and data sensitivity — without architectural changes.
Regulatory flexibility
When regulations restrict which models process certain data, compliance requirements change a config file, not the application.
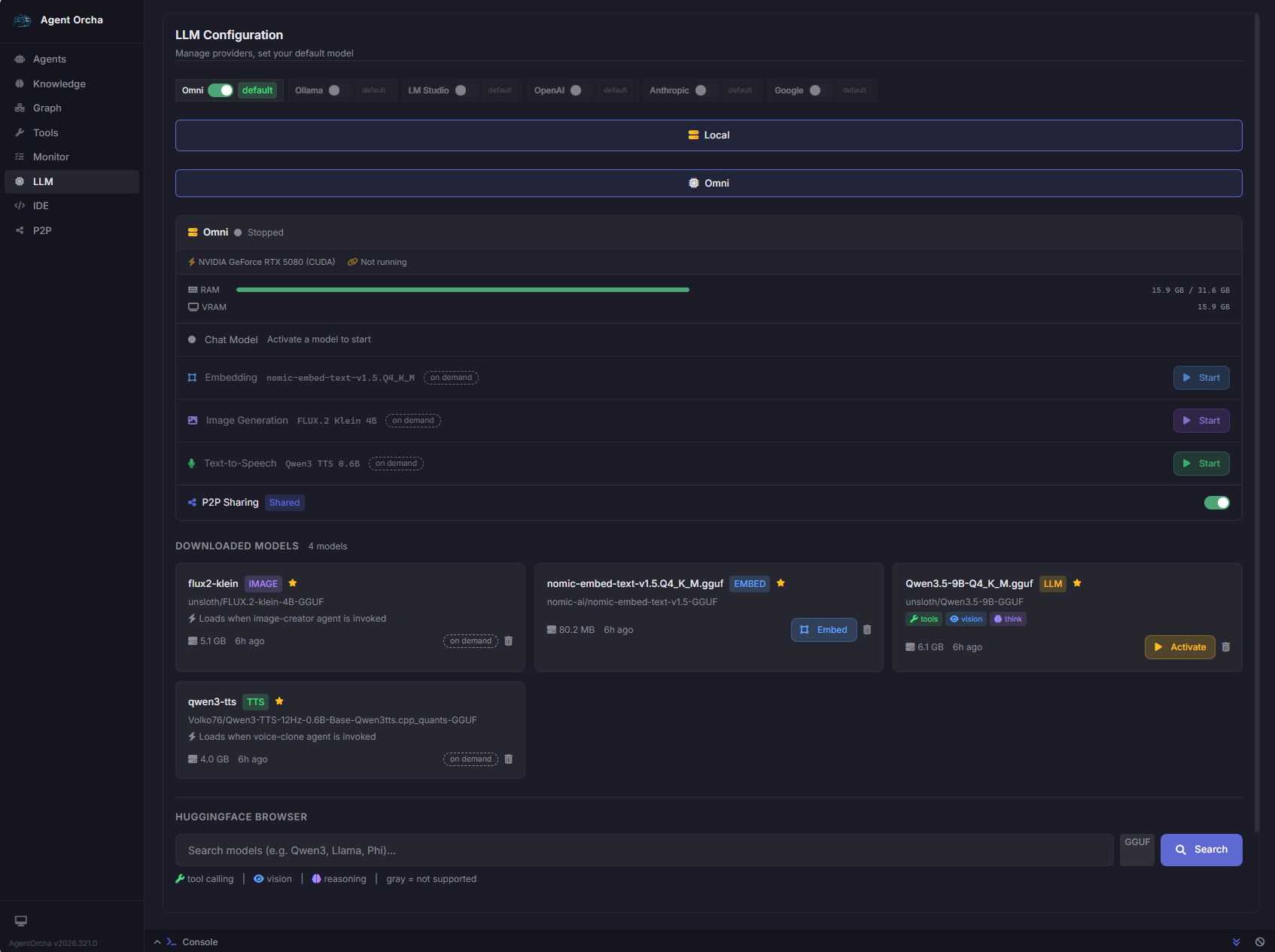
Why built-in model management — not Ollama, not LM Studio
Zero external dependencies
Most "local model support" depends on Ollama or vLLM as separate services. Agent Orcha's unified runtime manages the model lifecycle directly. One binary. One install.
- Auto GPU detection — NVIDIA CUDA, Apple Metal
- Text, image (FLUX.2), TTS (Qwen3), embeddings in one cache
- HuggingFace browser with one-click download
- Full visibility into model state and GPU utilization
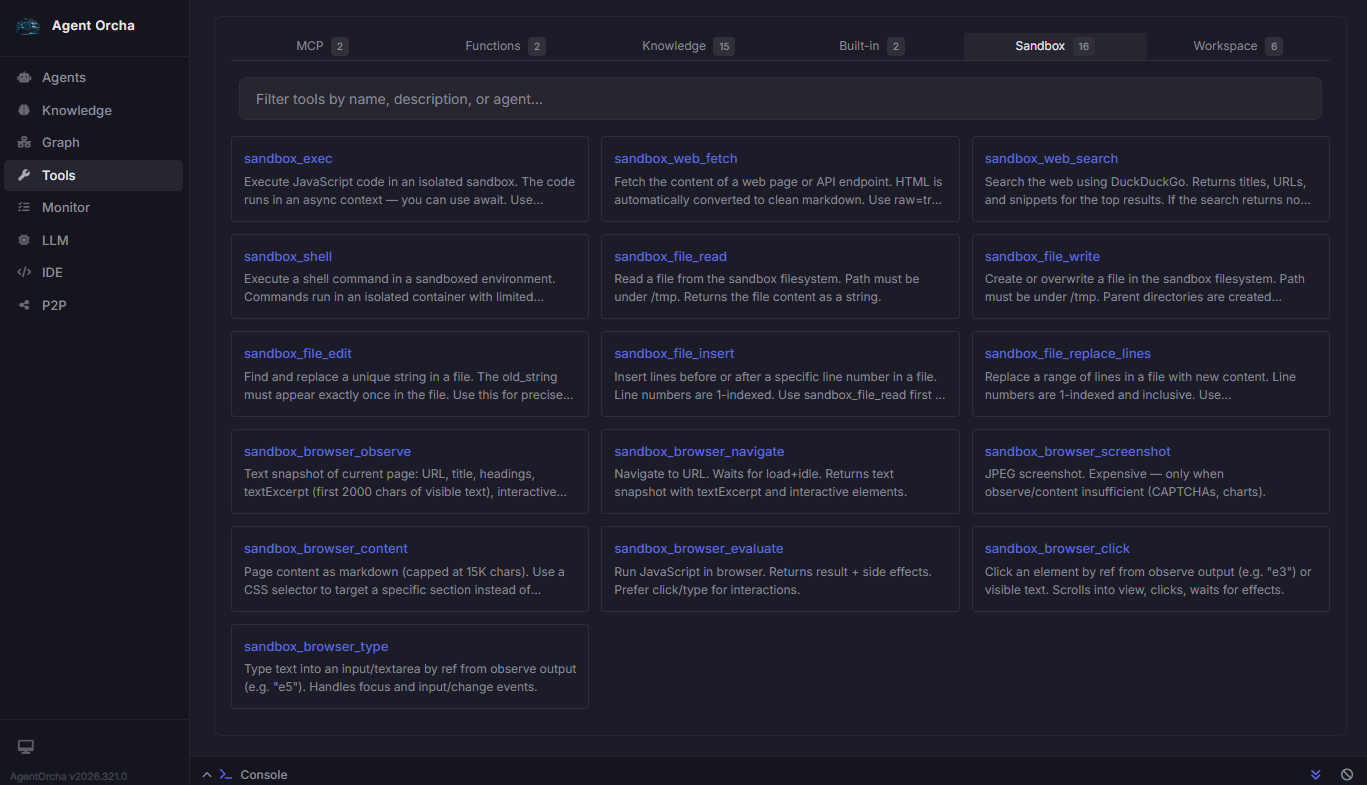
Why sandboxed execution — not "AI with access to your systems"
The architecture that gets through security review
Every agent operates within explicitly defined boundaries — scoped tool access, non-root containers, isolated VMs, and SSRF-protected network calls.
- 16 sandbox tools — shell, file ops, browser automation
- JavaScript VMs, non-root containers, CDP browsers
- SSRF protection, symlink escape prevention
- Every execution logged with inputs and outputs
Why built-in knowledge stores — not RAG-as-a-service
No external vector database
SQLite with sqlite-vec for vector storage. Embedded, no separate service, works air-gapped, backs up with a file copy.
Data stays local
Built-in knowledge stores keep everything on the same machine as the agents. No embeddings leaving your environment.
Vector + graph retrieval
Combine chunk-level vector search with entity and relationship graph traversal for contextually complete results.
Connect to data where it lives
PostgreSQL, MySQL, SQLite, files, web APIs. Auto-chunking, embedding, indexing, and reindexing on schedule.
Why declarative YAML — not code, not a GUI
Version-controlled infrastructure
Every config is a YAML file in git. Changes go through PRs. Roll back with a commit. Fits how infrastructure teams already work.
CI/CD native
Deploy through the same pipelines as your infrastructure. No manual web UI configuration that drifts from source control.
Accessible to non-developers
YAML is readable by security reviewers and compliance auditors. The visual composer generates valid YAML for teams that prefer a GUI.
Why peer-to-peer — not a central server
No single point of failure
Each node operates independently. Nodes discover, share agents and LLM capacity, and continue if any peer disconnects.
Credentialed private networks
Network key is SHA-256 hashed. Only peers sharing the key can discover each other. End-to-end Noise encryption.
Shared LLM capacity
One GPU node shares inference across the office without distributing API keys. Per-peer rate limiting prevents abuse.
Distributed teams
Share agents across locations without a central datacenter. If the network link drops, local agents keep running.
See the architecture in your environment
We'll walk your team through the platform, answer architectural questions, and scope a deployment against your actual use cases. Two weeks to production, or your money back.
Schedule a Demo